Kubernetes中CPU和内存使用限制与监控
容器的内存和 CPU 资源是最应该重视的两个资源,我之前所在的公司就因为容器 CPU Throttling 问题导致 Redis 集群故障,越是延迟敏感型应用越是要注意。
介绍
使用 Kubernetes 时,内存不足(OOM)错误和 CPU 限制(Throttling)是云应用程序中资源处理的主要难题。为什么呢?
云应用程序中的 CPU 和内存要求变得越来越重要,因为它们与您的云成本直接相关。
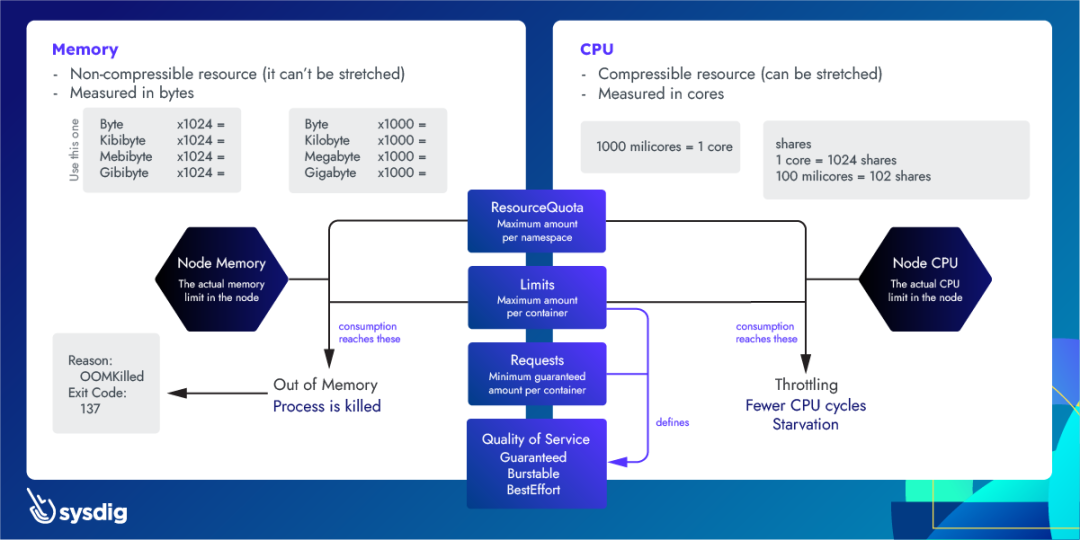
通过 limits 和 requests,您可以配置 pod 应如何分配内存和 CPU 资源,以防止资源匮乏并调整云成本。
如果节点没有足够的资源,Pod 可能会因抢占或节点压力而被驱逐。
当进程运行内存不足 (OOM) 时,它会因为没有所需的资源而被 Kill。
如果 CPU 消耗高于实际 limits,进程将开始受到限制。
OK,如何监控 Pod 快要 OOM 了,或者 CPU 快要被限制了呢?
Kubernetes OOM
Pod 中的每个容器都需要内存才能运行。
Kubernetes limits 是在 Pod 定义或 Deployment 定义中为每个容器设置的。
所有现代 Unix 系统都有一种方法可以杀死进程,以此回收内存(没用空闲内存的时候,只能杀进程了)。这个错误将被标记为 137 错误码或 OOMKilled。
State: Running
Started: Thu, 10 Oct 2019 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Thu, 10 Oct 2019 11:04:03 +0200
Finished: Thu, 10 Oct 2019 11:14:11 +0200
退出代码 137 意味着该进程使用的内存超过允许的数量,必须被 OS 终止。
这是 Linux 中的一项功能,内核为系统中运行的进程设置 oom_score 值。此外,它还允许设置一个名为 oom_score_adj 的值,Kubernetes 使用该值来实现服务质量。它还具有 OOM Killer,它将检查进程并终止那些使用超过过多内存(比如申请了超过 limits 限制的数量的内存)的进程。
请注意,在 Kubernetes 中,进程可能会达到以下任何限制:
在容器上设置的 Kubernetes 限制。
在 namespace 上设置的 Kubernetes ResourceQuota。
节点的实际内存大小。
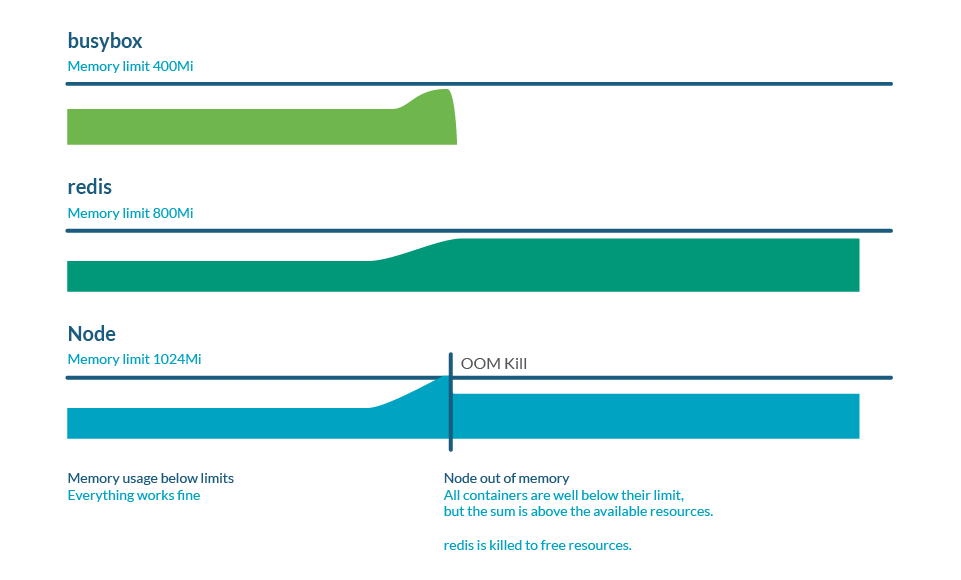
内存过量分配(overcommitment)
限制(limits)可以高于请求(requests),因此所有限制的总和可以高于节点容量。这称为过量分配,而且很常见。实际上,如果所有容器使用的内存多于 request 的内存,则可能会耗尽节点中的内存。这通常会导致一些 pod 死亡,以释放一些内存。
监控 Kubernetes OOM
在 Prometheus 生态中,使用 node-exporter 时,有一个名为 node_vmstat_oom_kill 的指标。跟踪 OOM 终止何时发生非常重要,但您可能希望在此类事件发生之前抢占先机并了解其情况。
我们更希望的是,检查进程与 Kubernetes limits 的接近程度:
(sum by (namespace,pod,container)
(rate(container_cpu_usage_seconds_total{container!=""}[5m])) / sum by
(namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"})) > 0.8
Kubernetes CPU throttling
CPU 限制(throttling)是一种当进程即将达到某些资源限制时减慢速度的行为。与内存情况类似,这些限制可能是:
在容器上设置的 Kubernetes limits。
在命名空间上设置的 Kubernetes ResourceQuota。
节点的实际算力大小。
想想下面的类比。我们有一条高速公路,交通流量如下:
CPU 就好比一条路
车辆代表 Process,每辆车都有不同的尺寸
多个通道代表有多个 CPU 核心
request 将是一条专用道路,例如自行车道
这里的 throttling 被表示为交通拥堵:最终,所有进程都会运行,但一切都会变慢。
Kubernetes 中的 CPU 处理逻辑
CPU 在 Kubernetes 中通过 shares 进行处理。每个 CPU 核心被分为 1024 个 shares,然后使用 Linux 内核的 cgroups(control groups)功能在运行的所有进程之间进行划分。
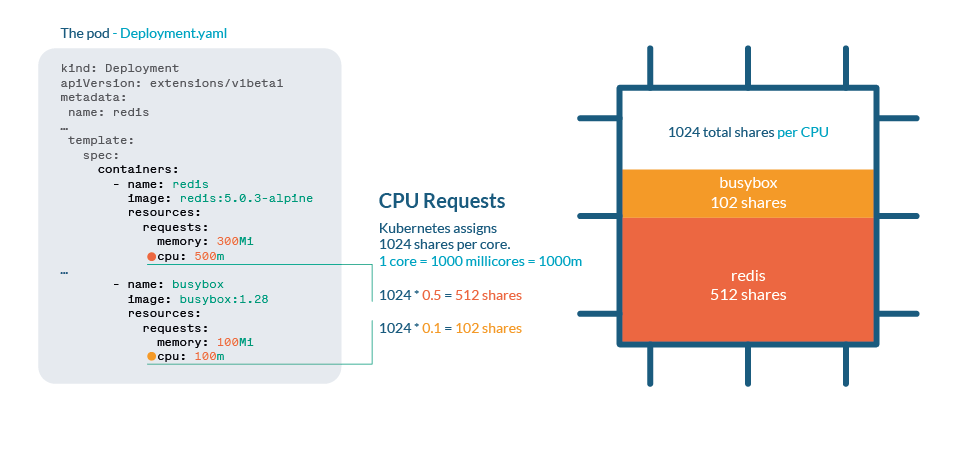
如果 CPU 可以处理当前所有进程,则无需执行任何操作。如果进程使用超过 100% 的 CPU,shares 机制就要起作用了。与任何 Linux 内核一样,Kubernetes 使用 CFS(Completely Fair Scheduler)机制,因此拥有更多份额的进程将获得更多的 CPU 时间。
与内存不同,Kubernetes 不会因为限流而杀死 Pod。
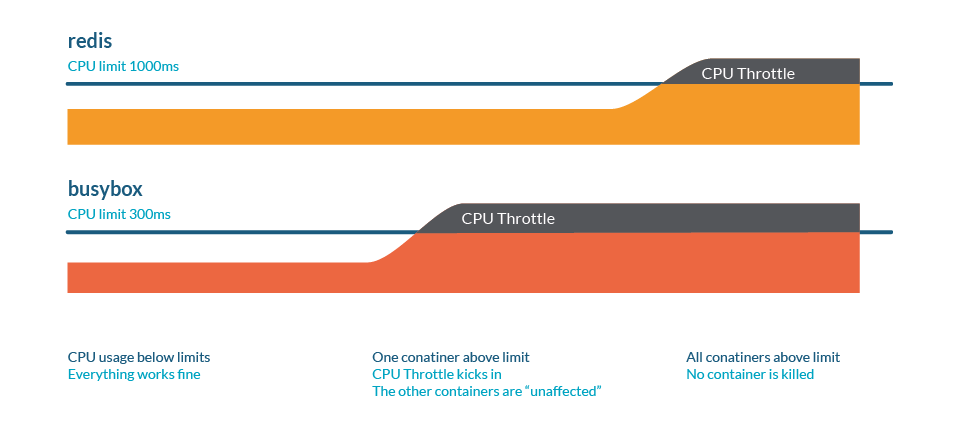
CPU 过渡分配
正如我们在limits 和 requests 文章中看到的,当我们想要限制进程的资源消耗时,设置 limits 或 requests 非常重要。尽管如此,请注意不要将总 requests 设置为大于实际 CPU 大小,每个容器都应该有保证的 CPU。
监控 Kubernetes CPU throttling
您可以检查进程与 Kubernetes limits 的接近程度:
(sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total
{container!=""}[5m])) / sum by (namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"}))
如果我们想要跟踪集群中发生的限制量,cadvisor 提供了 container_cpu_cfs_throttled_periods_total 和 container_cpu_cfs_periods_total 两个指标。通过这两个指标,您可以轻松计算所有 CPU 周期内的限制百分比。
最佳实践
注意 limits 和 requests
Limits 是在节点中设置资源最大上限的一种方法,但需要谨慎对待,因为您可能最终会受到限制或终止进程。
准备好应对驱逐
通过设置非常低的请求,您可能认为这将为您的进程授予最少的 CPU 或内存。但 kubelet 会首先驱逐那些使用率高于请求的 Pod,因此就相当于您将这些进程标记为最先被杀死的!
如果您需要保护特定 Pod 免遭抢占(当 kube-scheduler 需要分配新 Pod 时),请为最重要的进程分配 Priority Classes。
Throttling 是一个无声的敌人
设置不切实际的 limits 或过度使用,您可能没有意识到您的进程正在受到限制并且性能受到影响。主动监控 CPU 用量,了解确切的容器和命名空间层面的限制,及时发现问题非常重要。
附
下面这张图,比较好的解释了 Kubernetes 中 CPU 和内存的限制问题。供参考: